硬盘与显卡的访问与控制
硬盘的访问与控制
给汇编程序分段
section是nasm汇编编译器的关键字。首先nasm可以理解以汇编编译器程序,主要进行汇编语言的编译,也就是生成机器码。section成为节,主要是为了对程序进行模块化的划分,是汇编程序的结构更加的清晰。section的几个参数我们要着重了解一下。
1 | section 段名 align=对齐倍数 vstart=设置 |
若没有align子句在32位和64位程序中段与段间按照4字节对齐,及在原有段后补充0
若没有vstart子句,则段内汇编地址就是相对程序开的的偏移量,若指定vstart则段内汇编地址从vstart开始
1 | section data1 align=16 vstart=0 |
正如我们刚刚讨论过的,每个段都有一个汇编地址,它是相对于整 个程序开头(0)的。为了方便取得该段的汇编地址,NASM 编译器提供 了以下的表达式,可以用在你的程序中:
1 | section.段名称.start |
段 “code” 相 对 于 整 个 程 序 开 头 的 汇 编 地 址 是 section.code.start。
加载器和用户程序
一般来说,加载器和用户程序是在不同的时间、不同的地方,由不同的人或公司开发的。这就意味着,它们彼此并不了解对方的结构和功能。事实上,也不需要了解。加载器必须了解一 些必要的信息,虽然不是很多,但足以知道如何加载用户程序,他们之间必须有一个协议,或者说协定,比如说,在用户程序内部的某个固定位置,包含一些基本的结构信息,每个用户程序都必须把自己的情况放在这里,而加载器也固定在这个位置读取。经验表明,把这个约定的地点放在用户程序的开头,对双方,特别是对加载器来说比较方便,这就是用户程序头部。
头部需要在源程序以一个段的形式出现section header vestart=0而且,因为它是“头部”,所以,该段当然必须是第一个被定义的段, 且总是位于整个源程序的开头。
用户程序头部起码要包含以下信息。
- 用户程序的尺寸,即以字节为单位的大小。这对加载器来说是很 重要的,加载器需要根据这一信息来决定读取多少个逻辑扇区
- 应用程序的入口点,包括段地址和偏移地址。加载器并不清楚用 户程序的分段情况,更不知道第一条要执行的指令在用户程序中的位 置。因此,必须在头部给出第一条指令的段地址和偏移地址,这就是所 谓的应用程序入口点
- 段重定位表。用户程序可能包含不止一个段,比较大的程序可能 会包含多个代码段和多个数据段。这些段如何使用,是用户程序自己的 事,但前提是程序加载到内存后,每个段的地址必须重新确定一下。
1 | SECTION header vstart=0 ;定义用户程序头部段 |
加载器的工作流程
读取用户程序的起始扇区
把整个用户程序都读入内存
计算段的物理地址和逻辑地址和段地址(段重定位)
转移到用户程序执行(将处理器的控制权交给用户程序)
输入输出端口的访问
处理器是通过端口(Port)来和外围设备打交道的。本质 上,端口就是一些寄存器,类似于处理器内部的寄存器。不同之处仅仅 在于,这些叫做端口的寄存器位于I/O 接口电路中。端口是处理器和外围设备通过I/O 接口交流的窗口,每一个I/O 接口 都可能拥有好几个端口,分别用于不同的目的。端口可以是8 位的,也可以是16 位的或32位
比如,连接硬盘的 PATA/SATA 接口就有几个端口,分别是命令端口(当向该端口写入0x20 时,表明是从硬盘读数据;写入0x30 时,表明是向硬盘写数据)、状态端口(处理器根据这个端口的数据来判断硬盘工作是否正常,操作是否成功,发生了哪种错误)、参数端口(处理器通过这些端口告诉硬盘读 写的扇区数量,以及起始的逻辑扇区号)和数据端口(通过这个端口连续地取得要读出的数据,或者通过这个端口连续地发送要写入硬盘的数据)。
端口在不同的计算机系统中有着不同的实现方式。在一些计算机系 统中,端口号是映射到内存地址空间的。比如,0x00000~0xE0000 是 真实的物理内存地址,而0xE0001~0xFFFFF 是从很多I/O 接口那里映 射过来的,当访问这部分地址时,实际上是在访问I/O 接口。
而在另一些计算机系统中,端口是独立编址的,不和内存发生关系在这种计算机中,处理器的地址线既连接内存,也连接每一个I/O 接口。但是,处理器还有一个特殊的引脚M/IO#,在这 里,“#”表示低电平有效。也就是说,当处理器访问内存时,它会让 M/IO#引脚呈高电平,这里,和内存相关的电路就会打开;相反,如果处理器访问I/O 端口,那么M/IO#引脚呈低平,内存电路被禁止。与此同时,处理器发出的地址和M/IO#信号一起用于打个某个I/O 接口,如果该 I/O 接口分配的端口号与处理器地址相吻合的话。
in out 指令
1 | in al , dx |
in 指令的目的操作数必须是寄存器AL 或者AX,当访问8 位的端口时,使用寄存器AL;访问16 位的端口时,使用AX。in 指令的源操作数应当是寄存器DX,in 指令不允许使用别的通用寄存器,也不允许使用内存单元作为操作数。
in指令的目的操作数是立即数时,只能访问0~255(0x00~0xff)号端口,不允许访问大于255 的端口号
out 指令正好和in 指令相反,目的操作数可以是8 位立即数或者寄存器DX,源操作数必须是寄存器AL 或者AX
1 | out 0x37 , al ;写0x37号端口(8位端口) |
in out指令不影响flag寄存器
通过硬盘控制器端口读扇区数据
硬盘读写的基本单位是扇区。就是说,要读就至少读一个扇区,要写就至少写一个扇区
LBA模式(Logical Block Addressing)采用逻辑扇区号的方式访问硬盘,采用LBA28访问硬盘及扇区号由28位bit决定
主硬盘分配器分配了8个端口(0x1f0 ~ 0x1f7)
设置要读取的扇区数量
1
2
3mov dx , 0x1f2 ;访问0x1f2端口
mov al , 0x01 ;设置扇区数量,当al中是0时意味着尧都区的扇区数为256
out dx , al ;设置读取的扇区数为1设置起始的LBA扇区号
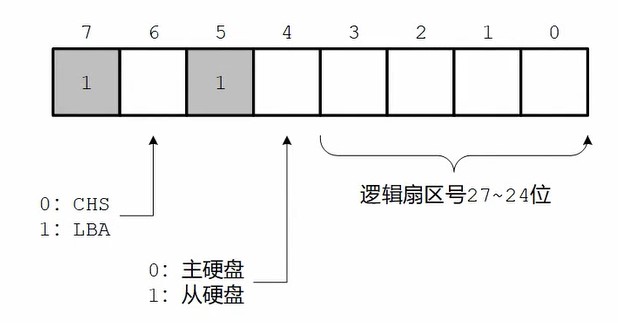
1
2
3
4
5
6
7
8
9
10
11
12;扇区号0x0 00 00 02
mov dx , 0x1f3
mov al , 0x02 ;LBA地址 7~0
out dx , al
inc dx ;0x1f4
mov al , 0x00
out dx , al
inc dx ;0x1f5
out dx , al
inc dx ;0x1f6
mov al , 0xe0 ;高8位 1110 第四位为0表示读写主硬盘,第六位位1表示采用LBA模式,7 5位固定为1
out dx , al设置读命令
1
2
3mov dx , 0x1f7
mov al , 0x20
out dx , al等待读写完成
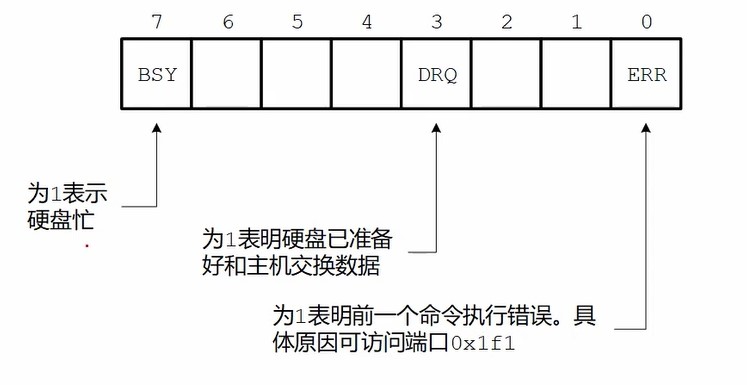
1
2
3
4
5
6mov dx , 0x1f7
.waits:
in al , dx
and al , 0x88
cmp al , 0x08 ;当无错误且准备好时不跳转
jnz .waits读硬盘
1
2
3
4
5
6
7
8;假定DS已指向存放扇区数据的段,BX里时段内的偏移地址
mov cx , 256
mov dx , 0x1f0
.readw:
in ax , dx
mov [bx] , ax
add bx , 2
loop .readw
比特位移动指令
1 | calc_segment_base: ;计算16位段地址 |
8086最大支持1M内存寻址,故地址有20位。我们将段地址高字节存放在寄存器dx低字节存放在寄存器ax,由于只能有20位故dx的高12位为0,由于是段地址故ax的第四位为0
add adr
8086无法进行32位加法,需要add和adc配合使用,adc是带进位的加法指令
1 | add ax , [cs:phy_base] |
在进行add后有可能产生进位,导致标志寄存器CF有可能为1,adc指令除了将操作数相加外还要加标志寄存器CF
shr ror shl rol
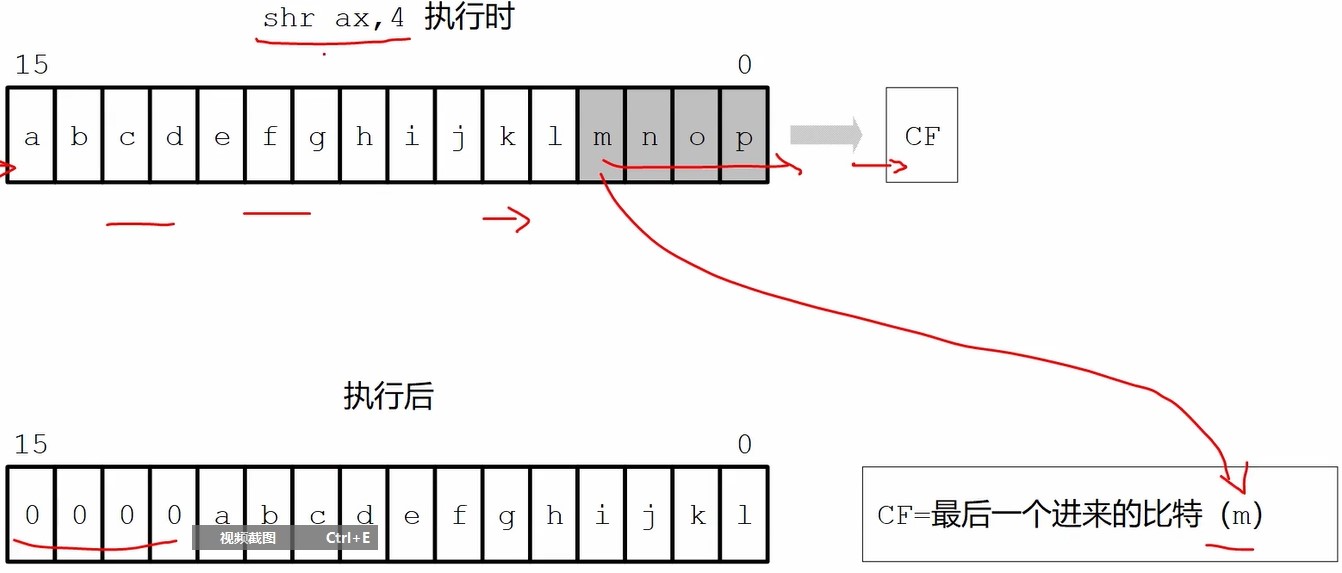
逻辑右移指令
1 | shr 寄存器/内存 , 立即数(8位) |
空余bit用0填充,标志寄存器CF=最后一个被移出的bit
循环右移指令ror
1 | ror 寄存器/内存 , 立即数(8位) |
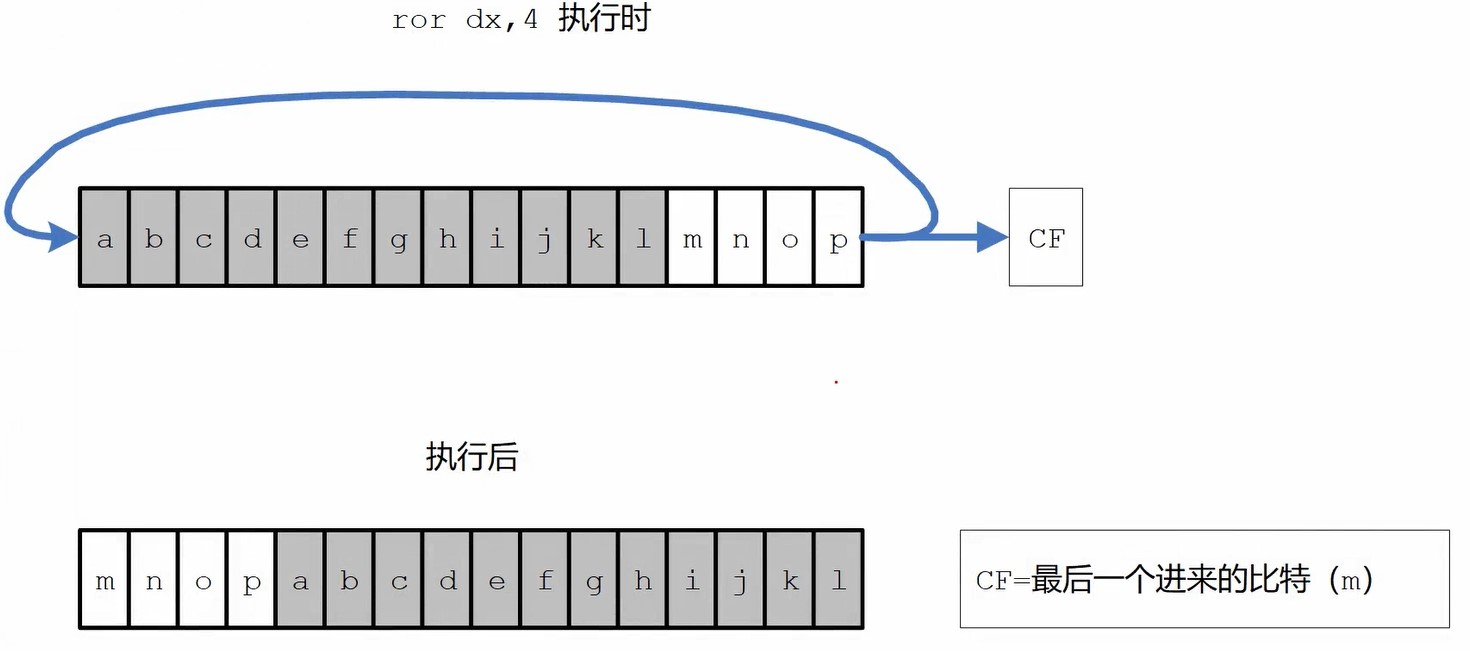
与shr ror相对应的是shl rol 逻辑左移和循环左移,sh -> shift(挪动) ro -> round圆
无条件转移指令
1 | jmp short 标号 ;机器码 EB 一字节相对地址 |
16位间接近转移
1 | jmp 寄存器/内存 ;直接转移到目标位置 |
16位绝对远转移
1 | jmp 段地址:偏移地址 |
16位间接绝对远转移
1 | jmp far 内存 ;在指定的内存地址处必须包含目标位置的段地址和偏移地址,第一个字是偏移地址ip,第二个字是段地址cs |
内存保留指令
1 | resb 立即数 :保留立即数字节的内存,不初始化 |
retf指令
CPU执行retf指令时,进行下面两步操作:
- (IP) = ((ss) * 16 + (sp))
- (SP) = (sp) + 2
- (CS) = ((ss) * 16 + (sp))
- (SP) = (sp) + 2