CAS 与 无锁队列
CAS 与 无锁队列
假设我们有一全局变量 idx , 在执行 idx++ 时编译器会翻译为三条汇编指令
1 | mov [idx] , %eax |
当三条汇编语句紧挨着执行时,idx++ 是保证正确的,但是当存在多个线程时 idx++ 的正确性就有待考证了如:
| 线程一 | 线程二 |
|---|---|
| mov [idx] , %eax | |
| inc %eax | |
| mov [idx] , %eax | |
| inc %eax | |
| mov %eax , [idx] | |
| mov %eax , [idx] |
当线程一和线程二按照这样的方式执行时,虽然在各自的线程中都执行了 idx++ 但是 idx 的结果只增加了一次 , 解决的方法可以是为临界区代码段添加互斥锁或自旋锁,对于互斥锁:当资源已被加锁时将会切换线程而自旋锁不会,自旋锁将在此线程上一直等待直到资源可用为止,二者的选择需要从资源的竞争程度与线程切换的开销方面考虑,这并不是这篇文章的重点,我们要写一个大多数人未知的东西(至少我是这样的)原子操作
汇编实现原子操作:
“最轻量级的锁”,通常也叫”原子操作”,之所以加引号是因为他们在汇编级别并不是原子操作,是用多条指令完成的,这些操作大多都是利用CPU支持的汇编指令
最常见的原子操作有Compare and Exchange,Self Increase/Decrease等等
80486 CPU 相关指令:
LOCK:这是一个指令前缀,在所对应的指令操作期间使此指令的目标操作数指定的存储区域锁定,以得到保护。
XADD:先交换两个操作数的值,再进行算术加法操作。多处理器安全,在80486及以上CPU中支持。
CMPXCHG:比较交换指令,第一操作数先和AL/AX/EAX比较,如果相等ZF置1,第二操作数赋给第一操作数,否则ZF清0,第一操作数赋给AL/AX/EAX。多处理器安全,在80486及以上CPU中支持。
XCHG:交换两个操作数,其中至少有一个是寄存器寻址.其他寄存器和标志位不受影响.
1 | /* |
在c++中atomic类提供了 cas 原子操作的方法如比较交互std::atomic<T>::compare_exchange_strong
cpu 亲和性
硬亲和性(affinity):简单来说就是利用 linux 内核提供给用户的 API,强行将进程或者线程绑定到某一个指定的 cpu 核运行。
在 Linux 内核中,所有的进程都有一个相关的数据结构,称为 task_struct 。这个结构非常重要,原因有很多;其中与亲和性(affinity)相关度最高的是 cpus_allowed 位掩码。这个位掩码由 n 位组成,与系统中的n个逻辑处理器一一对应。 具有 4 个物理 CPU 的系统可以有 4 位。如果这些 CPU 都启用了超线程,那么这个系统就有一个 8 位的位掩码。
如果为给定的进程设置了给定的位,那么这个进程就可以在相关的 CPU 上运行。因此,如果一个进程可以在任何 CPU 上运行,并且能够根据需要在处理器之间进行迁移,那么位掩码就全是 1。实际上,这就是 Linux 中进程的缺省状态。
Linux 内核 API 提供了一些方法,让用户可以修改位掩码或查看当前的位掩码:
1 |
|
示例代码:
1 | void process_affinity(int num) { // 设置进程 cpu 亲和性 |
通过 htop 可以看到在 usleep 结束之前有两个 cpu 的占用率是 100% 而其他线程占用几乎为 0,这说明两个线程分别绑定到了两个逻辑核心上
补充:
main函数结束后相当于调用exit,这将导致整个进程结束,意味着其他线程如 detach 后的线程也跟着结束,由于这里尝试多次没有看到希望的效果,当然也可以使用posix_exit()令主线程退出,而不影响其他线程
无锁队列(zeromq)
为什么需要无锁队列:
Cache 损坏
拿互斥锁来说,采用休眠等待,线程被频繁抢占产生的Cache损坏将导致应用程序性能下降。在同步机制上的争抢队列
由于锁机制,当资源争取发生的频率很高时,任务将大量的时间 (睡眠,等待,唤醒)浪费在获得保护队列数据的互斥锁,而不是处理队列中的数据上。动态内存分配
当一个任务从堆中分配内存时,标准的内存分配机制会 阻塞所有与这个任务共享地址空间的其它任务(进程中的所有线程)
提供的原子操作
atom_op.h
1 |
|
atomic_ptr.hpp 中对模板类型参数T的指针提供了原子操作,那其中一条进行分析
1 | inline T *cas (T *cmp_, T *val_) // if(cmp == ptr) 则 ptr=val 返回旧值 , 不相等直接返回ptr |
无锁队列的实现(单读单写)
yqueue 数据结构
yqueue是一种高效的队列实现。 主要目标是最大限度地减少所需的分配/解除分配次数。 因此,yqueue以N批为单位分配/解除分配元素。
1 | template <typename T, int N> |
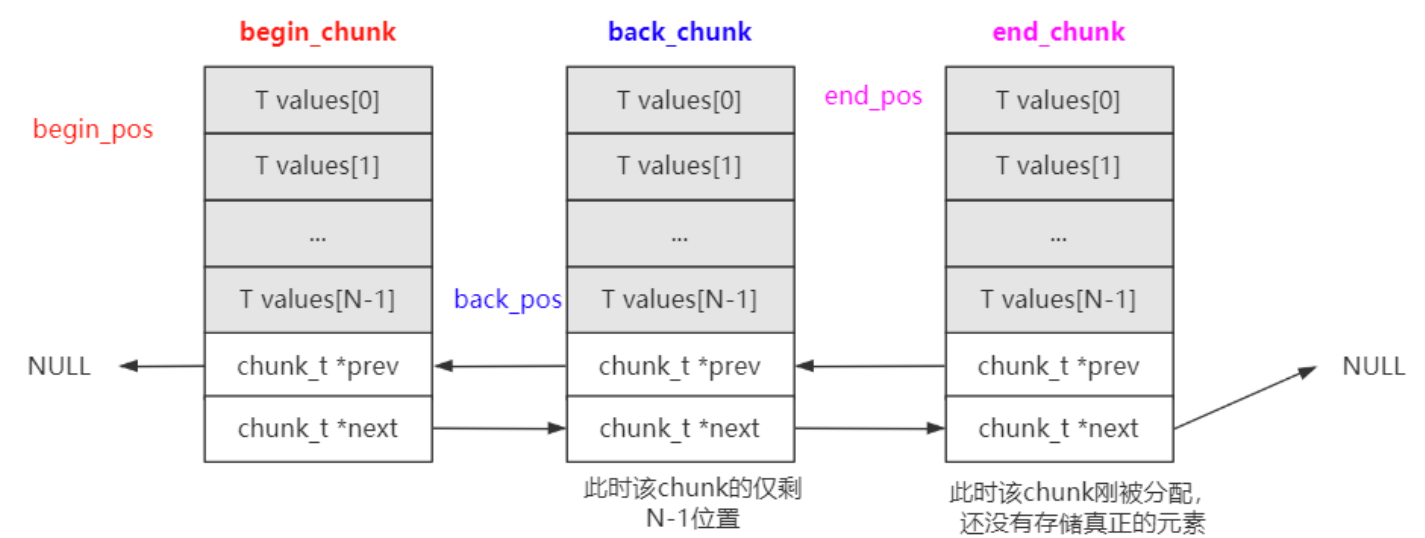
yqueue 内部是由一个个 chunk_t 组成的,使用双向链表的数据结构
1 | struct chunk_t |
chunk_t的组织方式
ypipe
ypipe_t在yqueue_t的基础上构建一个单写单读的无锁队列
ypipe内维护的成员变量:
1 | protected: |
构造函数:
1 | inline ypipe_t() |
write unwrite:写入可以单独写,也可以批量写。可以看到如果incomplete_ = true,则说明在批量写,直到incomplete_ = false时,进行写提交刷新 f 指针。
1 | // Write an item to the pipe. Don't flush it yet. If incomplete is |
flush
1 | // Flush all the completed items into the pipe. Returns false if |
以下参考文章中提供了多读多写的基于数据的无锁队列实现,以及理论分析
内联汇编:https://www.jianshu.com/p/1782e14a0766
cas 单例模式:https://blog.csdn.net/q5707802/article/details/79251491