决胜网络协议
序列号回绕
我们这里假设只有 8位 用来描述 tcp 的序列号
seq1 = 255 seq2 = 1
使用减法来判断包的先后顺序 ,
1 | static inline bool before(__u32 seq1, __u32 seq2) |
这里就变为了 before(0b1111 , 0b1) -> return 0b1110 < 0 , 采用了无符号数减法转化为有符号数来粗略的判断,当seq1 和 seq2之间的间距 大于 0xc000 时就无法判断了,就需要使用额外的东西来判断如时间戳
窗口缩放
tcp头部中指定了窗口大小,使用了16位,这意味着最大窗口位 64k,由于现代网络传输速度的加快,64k有时不能满足要求,于是在这上面打了补丁也就有了窗口缩放,用窗口大小乘缩放因子得到时机的窗口大小,缩放因子是在三次握手中协商的,如下报文
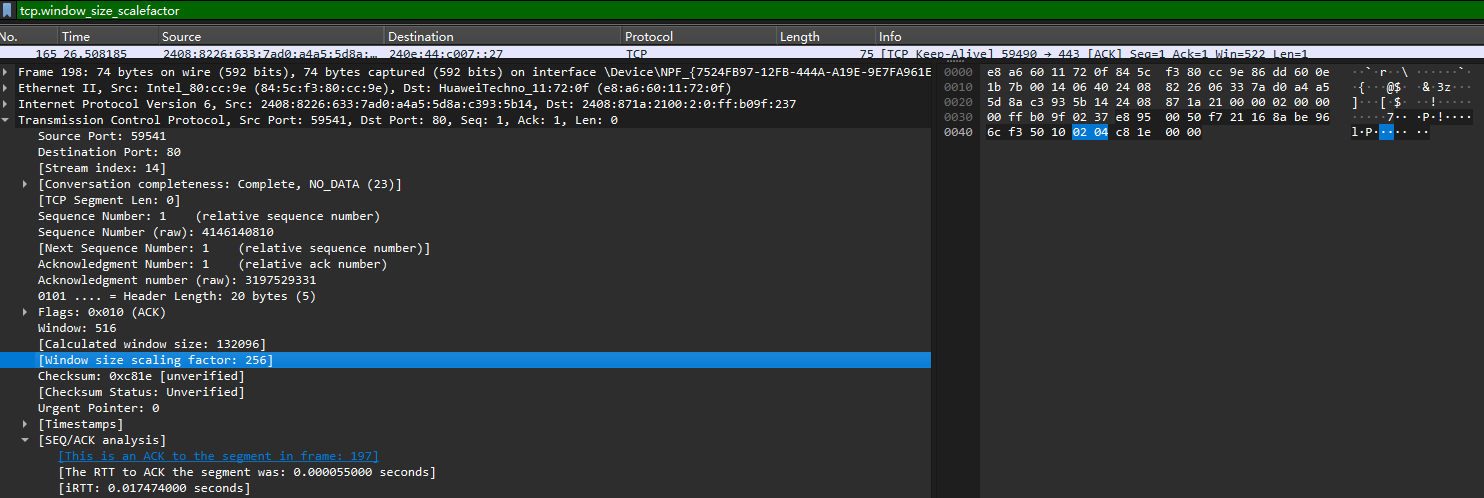
这里的缩放因子是 256 也就是实际的窗口大小为 516 * 256
tcp的重要选项
在 tcp头部中选项和填充属于可选字段,但也有相当重要的
MSS: 最大段大小选项 , TCP 允许的从对方接收的最大报文段
SACK: 选择确定选项
Window Scale: 窗口缩放选项
临时端口的分配
在没有调用 bind 或者 bind 指定的端口号为 0 的时候会采用临时端口号
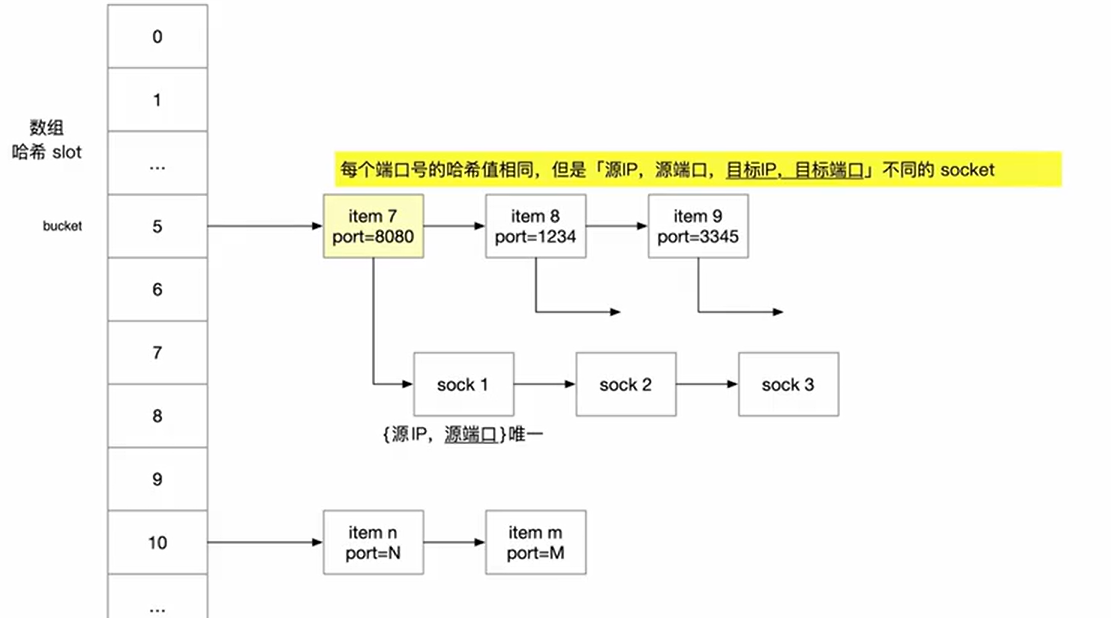
tcp协议栈用三个全局的 inet_hash 哈希表
- ehash: 负责有名的 socket,也就是四元组明确的 socket , key 是源地址 源端口 目的地址 目的端口组成的 , value 是对应的socket
- bhash: 负责端口分配,key是端口号,value 是使用此端口的所有socket,一个socket 可同时在bhash 和 ehash 中使用
- listening_hash: 负责 listen socket
1 | struct inet_hashinfo { |
inet_ehash_bucket 说是哈希表,实际就是一个数组,数组的每一个元素都是一个 inet_bind_hashbuchet 指针,chain 字段是一个链表
1 | struct inet_ehash_bucket { |
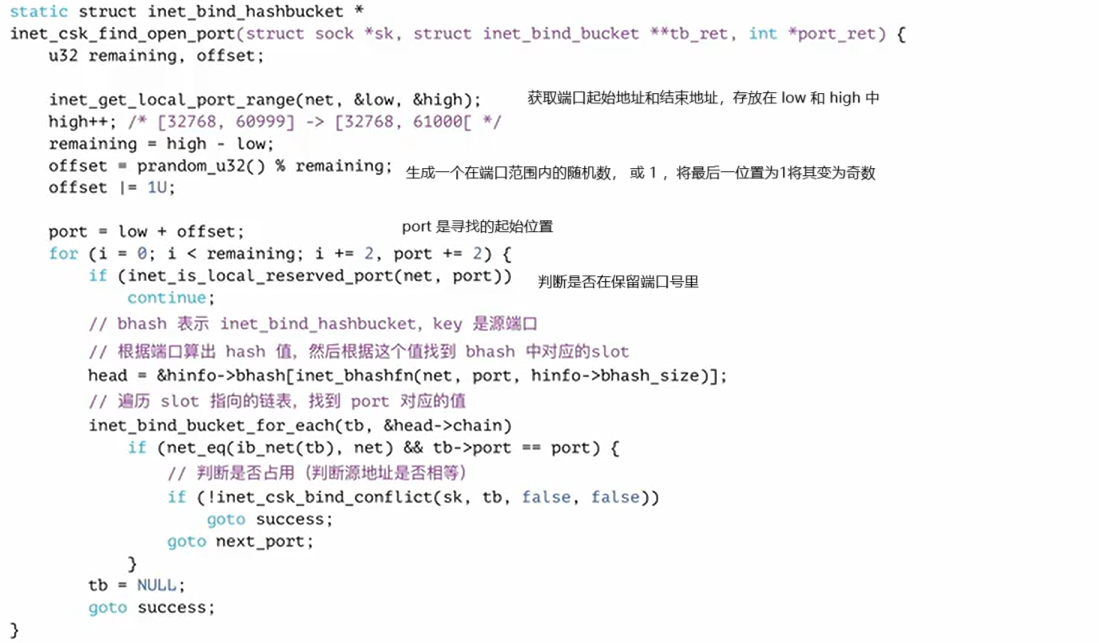
bind(0) 分配端口:
connect 分配端口:
首先要分配端口,与 bind(0) 不同的是 offset &= ~1,将offset 强制变为偶数之后与low相加检测bhash中是否有相同的 ,之后判断端口是否可用
对应 bind 端口为 0 时 ,所分配的临时端口是奇数,对应没有 bind 直接 connect ,所分配的端口是偶数
高版本内核临时端口分配策略
/proc/sys/net/ipv4/ip_local_port_range 文件指定了临时端口号的下界 low 和 上界 high,默认情况下 low 是偶数
2
32768 60999
- 优先给 bind(0) 分配随机的与low奇偶性不同的端口,也就是奇数,如果奇数端口号分配完了才需要尝试分配偶数端口
- 优先给 connect 分配随机的与low奇偶性相同的端口,也就是偶数
协议栈端口选择导致的性能衰减:当客户端疯狂 connect 时,1w并发连接和2w并发连接的耗时完全无线性关系,而是呈现一种近指数上升的趋势。例如,1w并发链接建连1w次,耗时不到1s,如果改为2w并发链接,建连2w次,耗时突然变成了10+s。当我们完全占用偶数组的端口后,所有后续的connect调用,所需的源端口应该位于奇数组中,然而该函数依旧会尝试完整遍历偶数组资源,这也就是__inet_check_established耗时占比这么高的原因。简而言之,就是自kernel 4.2开始,端口资源的分配策略改了,目前奇数端口留给bind,偶数端口留给connect为了均衡资源的占用,但是显然,这种策略不适合本文所述的特殊场景,并且对于bind而言,也存在性能衰减的问题。
为什么 SYN / FIN段不携带数据却要消耗一个序列号?
- 不占用序列号的段是不需要确认的,比如纯 ACK 包
- SYN 段需要双方确认,需要占用一个序列号,若不进行确认,对端将无法辨别所发出的 SYN 是否已经被收到
- 凡是消耗序列号的 TCP 报文段,一定需要对端确认。如果这个段没有收到确认,会一直重传直到达到指定的次数为至
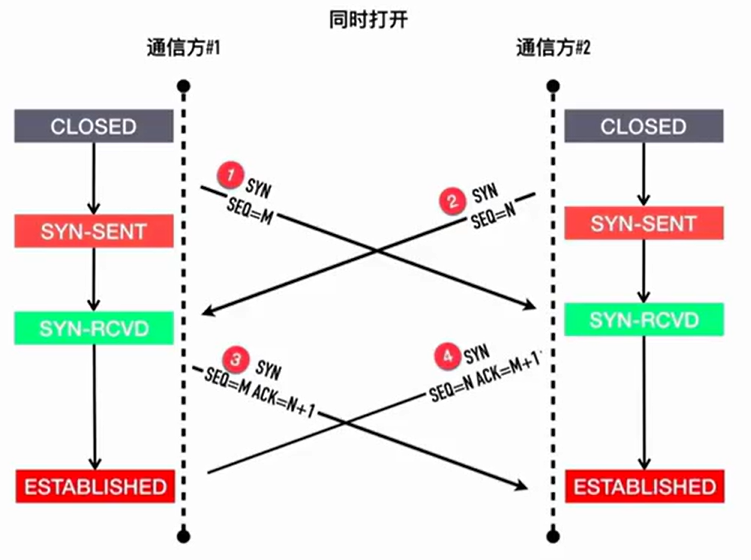
三次握手冷知识
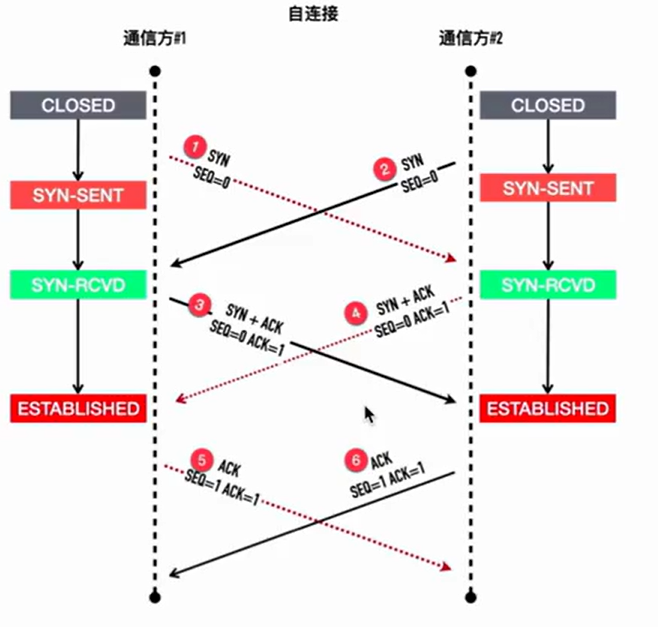
通信双方都知道对端开发的端口,同时调用 connect , 发送 syn 包,双方进入 SYN_SEND 状态,接收到对端传来的 SYN 时进入 SYN_REVD , 发送 SYN ACK , 进入 ESTABLISH
TCP 自连接:
当我们执行这段脚本:
1 | while ture |
过一段时间会出现
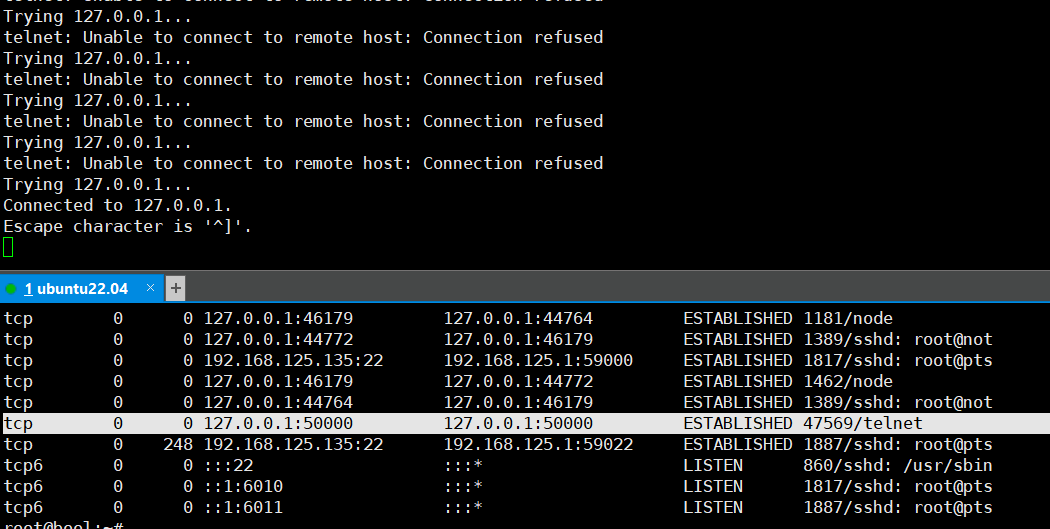
原理:
自连接的危害:
存在业务系统 B会访问本机服务 A , 服务A监听了 50000 端口
- 业务系统B代码中增加了对服务A断开重连的逻辑
- 如果有一个服务A挂掉长时间没有启动,业务系统B开始不断的 connect
- 系统B经过一段时间的重试就会出现自连接的情况
- 这是服务A想要监听50000断开就会出现断开被占用的情况
自连接的进程占用了端口,导致真正需要监听端口的服务程序无法正常启动,自连接的进程开启了connect成功了,实际上服务是不正常的,无法正常进行数据通信
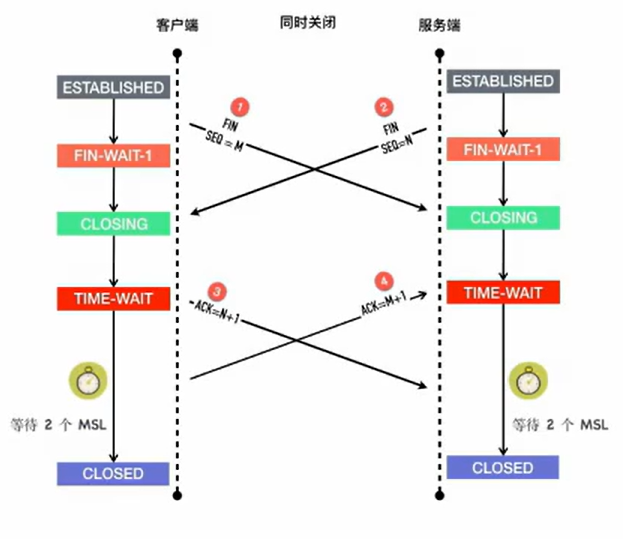
四次挥手中的同时关闭
两个队列
半连接队列(Incomplete connection queue), 又称 SYN 队列
全连接队列(Completed connection queue), 又称 Accept 队列
当客户端发起 SYN 到服务端,服务端收到以后会回 ACK 和⾃⼰的 SYN。这时服务端这边的 TCP 从 listen 状态变为 SYN_RCVD (SYN Received),此时会将这个连接信息放⼊半连接队列
int listen(int fd , int backlog)
TCP套接字上的backlog参数的行为在Linux 2.2中发生了变化。现在,它指定等待接受的完全建立的套接字的队列长度,而不是不完整连接请求的数量。不完整套接字队列的最大长度可以使用 /proc/sys/net/ipv4/tcp_max_syn_backlog 设置。当启用同步cookie时,没有逻辑上的最大长度,此设置将被忽略。
如果backlog参数大于 /proc/sys/net/core/somaxconn 中的值,那么它将被静默地截断为该值。自Linux 5.4以来,此文件中的默认值为4096
半连接队列的大小和传入的 backlog , 系统参数 somaxconn ,max_syn_backlog 都有关系,通过其中最小值用于计算,盲目的调大backlog 对最终半连接队列的大小可能不会有影响
全连接队列包含了服务端所有完成了三次握⼿,但是还未被应⽤取⾛的连接队列。此时的 socket 处于 ESTABLISHED 状态。每次应⽤调⽤ accept() 函数会移除队列头的连接。如果队列为空, accept() 通常会阻塞。全连接队列也被称为 Accept 队列。
半连接队列满了以后会忽略 SYN
全连接队列满了之后会忽略客户端的 ACK,随后重传 SYN + ACK,可以通过 /proc/sys/net/ipv4/tcp_abort_on_overflow 决定
tcp_abort_on_overflow为 0 表示三次握⼿最后⼀步全连接队列满以后 server 会丢掉 client 发过来的 ACK,服务端随后会进⾏重传 SYN+ACK。tcp_abort_on_overflow为 1 表示全连接队列满以后服务端直接 发送 RST 给客户端。
但是回给客户端 RST 包会带来另外⼀个问题,客户端不知道服务端 响应的 RST 包到底是因为「该端⼝没有进程监听」,还是「该端⼝ 有进程监听,只是它的队列满了」。
TCP的定时器
tcp 为每条连接建立了 7 个定时器:连接建立定时器,重传定时器,延迟ACK定时器,PERSIST定时器,KEEPALIVE定时器,FINWAIT2定时器,TIME_WAIT定时器
Persist 定时器是专⻔为零窗⼝探测⽽准备的。我们都知道 TCP 利⽤滑动窗⼝来实现流量控制,当接收端 B 接收窗⼝为 0 时,发送端 A 此时不 能再发送数据,发送端此时开启 Persist 定时器,超时后发送⼀个特殊的报⽂给接收端看对⽅窗⼝是否已经恢复,这个特殊的报⽂只有⼀个字节。
四次挥⼿过程中,主动关闭的⼀⽅收到 ACK 以后从 FINWAIT1 进⼊ FINWAIT2 状态等待对端的 FIN 包的到来,FINWAIT2 定时器的作 ⽤是防⽌对⽅⼀直不发送 FIN 包,防⽌⾃⼰⼀直傻等。这个值由 /proc/sys/net/ipv4/tcp_fin_timeout 决定,默认值为 60s
TIMEWAIT 定时器也称为 2MSL 定时器,可主动关闭连接的⼀⽅在 TIMEWAIT 持续 2 个 MSL 的时间,超时后端⼝号可被安全的重⽤。
TCP 拥塞控制
tcp 拥塞控制四大阶段:慢启动 , 拥塞避免 , 快速重传 , 快速恢复
在连接建⽴之初,你不知道对端有多快,如果有⾜够的带宽,你可以选择⽤最快的速度传输数据,但是如果 是⼀个缓慢的移动⽹络呢?如果发送的数据过多,只是造成更⼤的⽹络延迟。这是基于整 个考虑,每个 TCP 连接都有⼀个拥塞窗⼜的限制,最初这个值很⼩,随着时间的推移, 每次发送的数据量如果在不丢包的情况下,慢慢的递增,这种机制被称为「慢启动」
第⼀步,三次握⼿以后,双⽅通过 ACK 告诉了对⽅ ⾃⼰的接收窗⼜(rwnd)的⼤⼩,之后就可以互相发 数据了
第⼆步,通信双⽅各⾃初始化⾃⼰的「拥塞窗⼜」 (Congestion Window,cwnd)⼤⼩
第三步,cwnd 初始值较⼩时,每收到⼀个 ACK, cwnd + 1,每经过⼀个 RTT,cwnd 变为之前的两 倍。
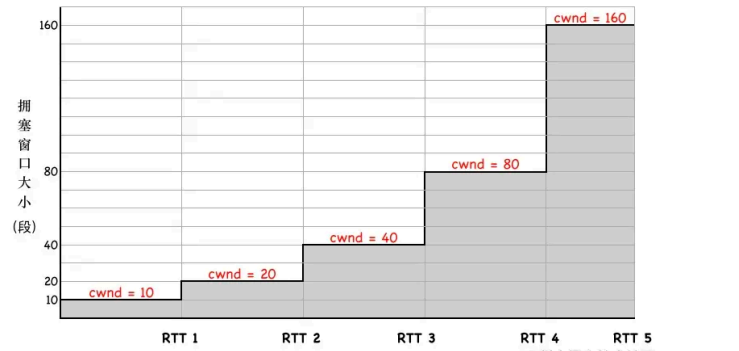
慢启动拥塞窗口(cwnd)肯定不能⽆⽌境的指数级增长下去,否则拥塞控制就变成了「拥塞失控」了,它的阈值称为「慢启动阈值」(Slow Start Threshold,ssthresh)。ssthresh 就是⼀道刹车,让拥塞窗⼜别涨那么快
- 当 cwnd < ssthresh 时,拥塞窗⼜按指数级增长(慢启动)
- 当 cwnd > ssthresh 时,拥塞窗⼜按线性增长(拥塞避免),在这个阶段,每⼀ 个往返 RTT,拥塞窗⼜⼤约增加 1 个 MSS ⼤⼩,直到检测到拥塞为⽌
当收到三次重复 ACK 时,进⼊快速恢复阶段。解释为⽹络轻度拥塞。
- 拥塞阈值 ssthresh 降低为 cwnd 的⼀半:ssthresh = cwnd / 2
- 拥塞窗⼜ cwnd 设置为 ssthresh
- 拥塞窗⼜线性增加